- prediction/image/ FastAPI 서버 Docker 환경 구성 - Dockerfile: PyTorch 2.1 + CUDA 12.1 기반 GPU 이미지 - docker-compose.yml: GPU 할당 + 데이터 볼륨 마운트 - requirements.txt: 서버 의존성 목록 - .env.example: 환경변수 템플릿 - DOCKER_USAGE.md: 빌드/실행/API 사용법 문서 - Dockerfile에 .dockerignore 제외 폴더 mkdir -p 추가 - .gitignore: prediction/image 결과물 및 모델 가중치(.pth) 제외 추가 - dbInsert_csv.py, dbInsert_shp.py 삭제 (미사용 DB 로직) - api.py: dbInsert import 및 주석 처리된 DB 호출 코드 제거 - aerialRouter.ts: req.params 타입 오류 수정
12 KiB
FastFCN
FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation
Introduction
Abstract
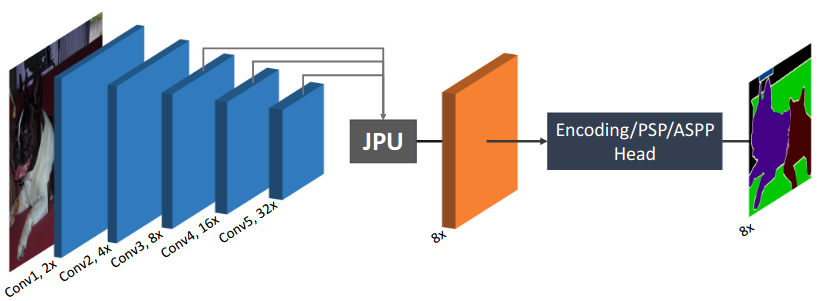
Modern approaches for semantic segmentation usually employ dilated convolutions in the backbone to extract high-resolution feature maps, which brings heavy computation complexity and memory footprint. To replace the time and memory consuming dilated convolutions, we propose a novel joint upsampling module named Joint Pyramid Upsampling (JPU) by formulating the task of extracting high-resolution feature maps into a joint upsampling problem. With the proposed JPU, our method reduces the computation complexity by more than three times without performance loss. Experiments show that JPU is superior to other upsampling modules, which can be plugged into many existing approaches to reduce computation complexity and improve performance. By replacing dilated convolutions with the proposed JPU module, our method achieves the state-of-the-art performance in Pascal Context dataset (mIoU of 53.13%) and ADE20K dataset (final score of 0.5584) while running 3 times faster.
Citation
@article{wu2019fastfcn,
title={Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation},
author={Wu, Huikai and Zhang, Junge and Huang, Kaiqi and Liang, Kongming and Yu, Yizhou},
journal={arXiv preprint arXiv:1903.11816},
year={2019}
}
Results and models
Cityscapes
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| FastFCN + DeepLabV3 | R-50-D32 | 512x1024 | 80000 | 5.67 | 2.64 | 79.12 | 80.58 | config | model | log |
| FastFCN + DeepLabV3 (4x4) | R-50-D32 | 512x1024 | 80000 | 9.79 | - | 79.52 | 80.91 | config | model | log |
| FastFCN + PSPNet | R-50-D32 | 512x1024 | 80000 | 5.67 | 4.40 | 79.26 | 80.86 | config | model | log |
| FastFCN + PSPNet (4x4) | R-50-D32 | 512x1024 | 80000 | 9.94 | - | 78.76 | 80.03 | config | model | log |
| FastFCN + EncNet | R-50-D32 | 512x1024 | 80000 | 8.15 | 4.77 | 77.97 | 79.92 | config | model | log |
| FastFCN + EncNet (4x4) | R-50-D32 | 512x1024 | 80000 | 15.45 | - | 78.6 | 80.25 | config | model | log |
ADE20K
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| FastFCN + DeepLabV3 | R-50-D32 | 512x512 | 80000 | 8.46 | 12.06 | 41.88 | 42.91 | config | model | log |
| FastFCN + DeepLabV3 | R-50-D32 | 512x512 | 160000 | - | - | 43.58 | 44.92 | config | model | log |
| FastFCN + PSPNet | R-50-D32 | 512x512 | 80000 | 8.02 | 19.21 | 41.40 | 42.12 | config | model | log |
| FastFCN + PSPNet | R-50-D32 | 512x512 | 160000 | - | - | 42.63 | 43.71 | config | model | log |
| FastFCN + EncNet | R-50-D32 | 512x512 | 80000 | 9.67 | 17.23 | 40.88 | 42.36 | config | model | log |
| FastFCN + EncNet | R-50-D32 | 512x512 | 160000 | - | - | 42.50 | 44.21 | config | model | log |
Note:
4x4means 4 GPUs with 4 samples per GPU in training, default setting is 4 GPUs with 2 samples per GPU in training.- Results of DeepLabV3 (mIoU: 79.32), PSPNet (mIoU: 78.55) and ENCNet (mIoU: 77.94) can be found in each original repository.