- prediction/image/ FastAPI 서버 Docker 환경 구성 - Dockerfile: PyTorch 2.1 + CUDA 12.1 기반 GPU 이미지 - docker-compose.yml: GPU 할당 + 데이터 볼륨 마운트 - requirements.txt: 서버 의존성 목록 - .env.example: 환경변수 템플릿 - DOCKER_USAGE.md: 빌드/실행/API 사용법 문서 - Dockerfile에 .dockerignore 제외 폴더 mkdir -p 추가 - .gitignore: prediction/image 결과물 및 모델 가중치(.pth) 제외 추가 - dbInsert_csv.py, dbInsert_shp.py 삭제 (미사용 DB 로직) - api.py: dbInsert import 및 주석 처리된 DB 호출 코드 제거 - aerialRouter.ts: req.params 타입 오류 수정
14 KiB
ISANet
Interlaced Sparse Self-Attention for Semantic Segmentation
Introduction
Abstract
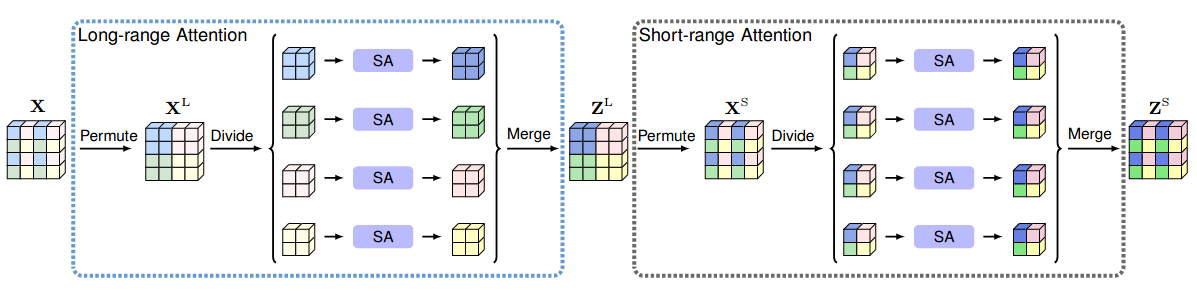
In this paper, we present a so-called interlaced sparse self-attention approach to improve the efficiency of the \emph{self-attention} mechanism for semantic segmentation. The main idea is that we factorize the dense affinity matrix as the product of two sparse affinity matrices. There are two successive attention modules each estimating a sparse affinity matrix. The first attention module is used to estimate the affinities within a subset of positions that have long spatial interval distances and the second attention module is used to estimate the affinities within a subset of positions that have short spatial interval distances. These two attention modules are designed so that each position is able to receive the information from all the other positions. In contrast to the original self-attention module, our approach decreases the computation and memory complexity substantially especially when processing high-resolution feature maps. We empirically verify the effectiveness of our approach on six challenging semantic segmentation benchmarks.
Citation
@article{huang2019isa,
title={Interlaced Sparse Self-Attention for Semantic Segmentation},
author={Huang, Lang and Yuan, Yuhui and Guo, Jianyuan and Zhang, Chao and Chen, Xilin and Wang, Jingdong},
journal={arXiv preprint arXiv:1907.12273},
year={2019}
}
The technical report above is also presented at:
@article{yuan2021ocnet,
title={OCNet: Object Context for Semantic Segmentation},
author={Yuan, Yuhui and Huang, Lang and Guo, Jianyuan and Zhang, Chao and Chen, Xilin and Wang, Jingdong},
journal={International Journal of Computer Vision},
pages={1--24},
year={2021},
publisher={Springer}
}
Results and models
Cityscapes
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| ISANet | R-50-D8 | 512x1024 | 40000 | 5.869 | 2.91 | 78.49 | 79.44 | config | model | log |
| ISANet | R-50-D8 | 512x1024 | 80000 | 5.869 | 2.91 | 78.68 | 80.25 | config | model | log |
| ISANet | R-50-D8 | 769x769 | 40000 | 6.759 | 1.54 | 78.70 | 80.28 | config | model | log |
| ISANet | R-50-D8 | 769x769 | 80000 | 6.759 | 1.54 | 79.29 | 80.53 | config | model | log |
| ISANet | R-101-D8 | 512x1024 | 40000 | 9.425 | 2.35 | 79.58 | 81.05 | config | model | log |
| ISANet | R-101-D8 | 512x1024 | 80000 | 9.425 | 2.35 | 80.32 | 81.58 | config | model | log |
| ISANet | R-101-D8 | 769x769 | 40000 | 10.815 | 0.92 | 79.68 | 80.95 | config | model | log |
| ISANet | R-101-D8 | 769x769 | 80000 | 10.815 | 0.92 | 80.61 | 81.59 | config | model | log |
ADE20K
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| ISANet | R-50-D8 | 512x512 | 80000 | 9.0 | 22.55 | 41.12 | 42.35 | config | model | log |
| ISANet | R-50-D8 | 512x512 | 160000 | 9.0 | 22.55 | 42.59 | 43.07 | config | model | log |
| ISANet | R-101-D8 | 512x512 | 80000 | 12.562 | 10.56 | 43.51 | 44.38 | config | model | log |
| ISANet | R-101-D8 | 512x512 | 160000 | 12.562 | 10.56 | 43.80 | 45.4 | config | model | log |
Pascal VOC 2012 + Aug
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| ISANet | R-50-D8 | 512x512 | 20000 | 5.9 | 23.08 | 76.78 | 77.79 | config | model | log |
| ISANet | R-50-D8 | 512x512 | 40000 | 5.9 | 23.08 | 76.20 | 77.22 | config | model | log |
| ISANet | R-101-D8 | 512x512 | 20000 | 9.465 | 7.42 | 78.46 | 79.16 | config | model | log |
| ISANet | R-101-D8 | 512x512 | 40000 | 9.465 | 7.42 | 78.12 | 79.04 | config | model | log |