DANet
Dual Attention Network for Scene Segmentation
Introduction
Official Repo
Code Snippet
Abstract
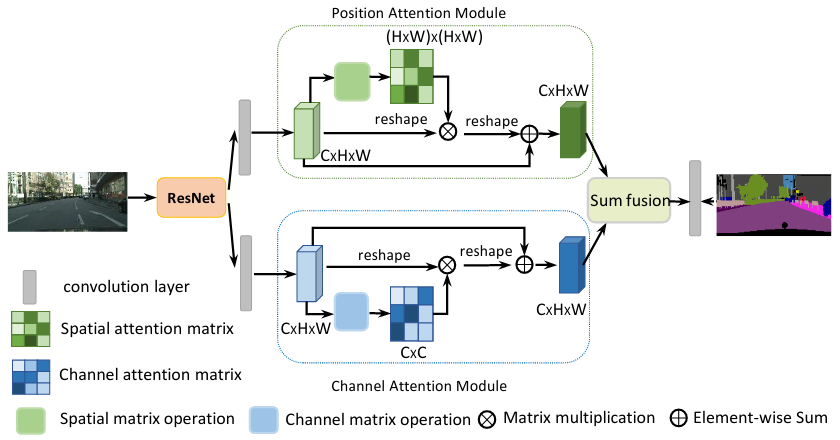
In this paper, we address the scene segmentation task by capturing rich contextual dependencies based on the selfattention mechanism. Unlike previous works that capture contexts by multi-scale features fusion, we propose a Dual Attention Networks (DANet) to adaptively integrate local features with their global dependencies. Specifically, we append two types of attention modules on top of traditional dilated FCN, which model the semantic interdependencies in spatial and channel dimensions respectively. The position attention module selectively aggregates the features at each position by a weighted sum of the features at all positions. Similar features would be related to each other regardless of their distances. Meanwhile, the channel attention module selectively emphasizes interdependent channel maps by integrating associated features among all channel maps. We sum the outputs of the two attention modules to further improve feature representation which contributes to more precise segmentation results. We achieve new state-of-the-art segmentation performance on three challenging scene segmentation datasets, i.e., Cityscapes, PASCAL Context and COCO Stuff dataset. In particular, a Mean IoU score of 81.5% on Cityscapes test set is achieved without using coarse data. We make the code and trained model publicly available at this https URL.
Citation
@article{fu2018dual,
title={Dual Attention Network for Scene Segmentation},
author={Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang,and Hanqing Lu},
booktitle={The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
Results and models
Cityscapes
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DANet |
R-50-D8 |
512x1024 |
40000 |
7.4 |
2.66 |
78.74 |
- |
config |
model | log |
| DANet |
R-101-D8 |
512x1024 |
40000 |
10.9 |
1.99 |
80.52 |
- |
config |
model | log |
| DANet |
R-50-D8 |
769x769 |
40000 |
8.8 |
1.56 |
78.88 |
80.62 |
config |
model | log |
| DANet |
R-101-D8 |
769x769 |
40000 |
12.8 |
1.07 |
79.88 |
81.47 |
config |
model | log |
| DANet |
R-50-D8 |
512x1024 |
80000 |
- |
- |
79.34 |
- |
config |
model | log |
| DANet |
R-101-D8 |
512x1024 |
80000 |
- |
- |
80.41 |
- |
config |
model | log |
| DANet |
R-50-D8 |
769x769 |
80000 |
- |
- |
79.27 |
80.96 |
config |
model | log |
| DANet |
R-101-D8 |
769x769 |
80000 |
- |
- |
80.47 |
82.02 |
config |
model | log |
ADE20K
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DANet |
R-50-D8 |
512x512 |
80000 |
11.5 |
21.20 |
41.66 |
42.90 |
config |
model | log |
| DANet |
R-101-D8 |
512x512 |
80000 |
15 |
14.18 |
43.64 |
45.19 |
config |
model | log |
| DANet |
R-50-D8 |
512x512 |
160000 |
- |
- |
42.45 |
43.25 |
config |
model | log |
| DANet |
R-101-D8 |
512x512 |
160000 |
- |
- |
44.17 |
45.02 |
config |
model | log |
Pascal VOC 2012 + Aug
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DANet |
R-50-D8 |
512x512 |
20000 |
6.5 |
20.94 |
74.45 |
75.69 |
config |
model | log |
| DANet |
R-101-D8 |
512x512 |
20000 |
9.9 |
13.76 |
76.02 |
77.23 |
config |
model | log |
| DANet |
R-50-D8 |
512x512 |
40000 |
- |
- |
76.37 |
77.29 |
config |
model | log |
| DANet |
R-101-D8 |
512x512 |
40000 |
- |
- |
76.51 |
77.32 |
config |
model | log |