- prediction/image/ FastAPI 서버 Docker 환경 구성
- Dockerfile: PyTorch 2.1 + CUDA 12.1 기반 GPU 이미지
- docker-compose.yml: GPU 할당 + 데이터 볼륨 마운트
- requirements.txt: 서버 의존성 목록
- .env.example: 환경변수 템플릿
- DOCKER_USAGE.md: 빌드/실행/API 사용법 문서
- Dockerfile에 .dockerignore 제외 폴더 mkdir -p 추가
- .gitignore: prediction/image 결과물 및 모델 가중치(.pth) 제외 추가
- dbInsert_csv.py, dbInsert_shp.py 삭제 (미사용 DB 로직)
- api.py: dbInsert import 및 주석 처리된 DB 호출 코드 제거
- aerialRouter.ts: req.params 타입 오류 수정
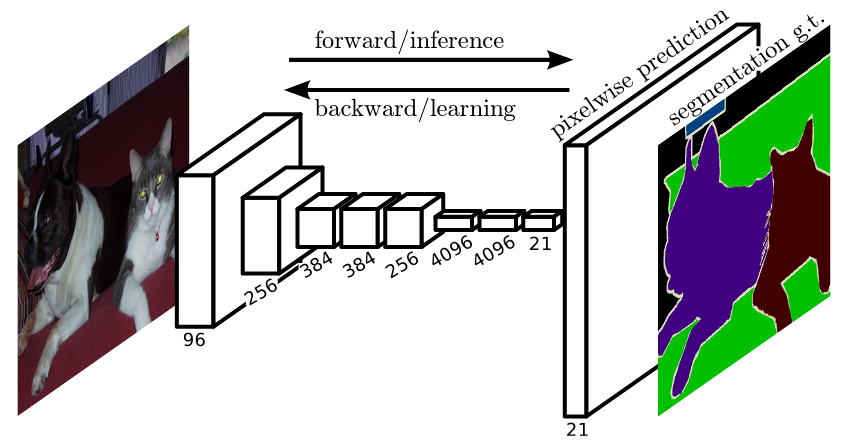
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
Citation
@article{shelhamer2017fully,title={Fully convolutional networks for semantic segmentation},author={Shelhamer, Evan and Long, Jonathan and Darrell, Trevor},journal={IEEE transactions on pattern analysis and machine intelligence},volume={39},number={4},pages={640--651},year={2017},publisher={IEEE Trans Pattern Anal Mach Intell}}