- prediction/image/ FastAPI 서버 Docker 환경 구성 - Dockerfile: PyTorch 2.1 + CUDA 12.1 기반 GPU 이미지 - docker-compose.yml: GPU 할당 + 데이터 볼륨 마운트 - requirements.txt: 서버 의존성 목록 - .env.example: 환경변수 템플릿 - DOCKER_USAGE.md: 빌드/실행/API 사용법 문서 - Dockerfile에 .dockerignore 제외 폴더 mkdir -p 추가 - .gitignore: prediction/image 결과물 및 모델 가중치(.pth) 제외 추가 - dbInsert_csv.py, dbInsert_shp.py 삭제 (미사용 DB 로직) - api.py: dbInsert import 및 주석 처리된 DB 호출 코드 제거 - aerialRouter.ts: req.params 타입 오류 수정 |
||
|---|---|---|
| .. | ||
| bisenetv2_fcn_4x4_1024x1024_160k_cityscapes.py | ||
| bisenetv2_fcn_4x8_1024x1024_160k_cityscapes.py | ||
| bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py | ||
| bisenetv2_fcn_ohem_4x4_1024x1024_160k_cityscapes.py | ||
| bisenetv2.yml | ||
| README.md | ||
BiSeNetV2
Bisenet v2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
Introduction
Official Repo
Abstract
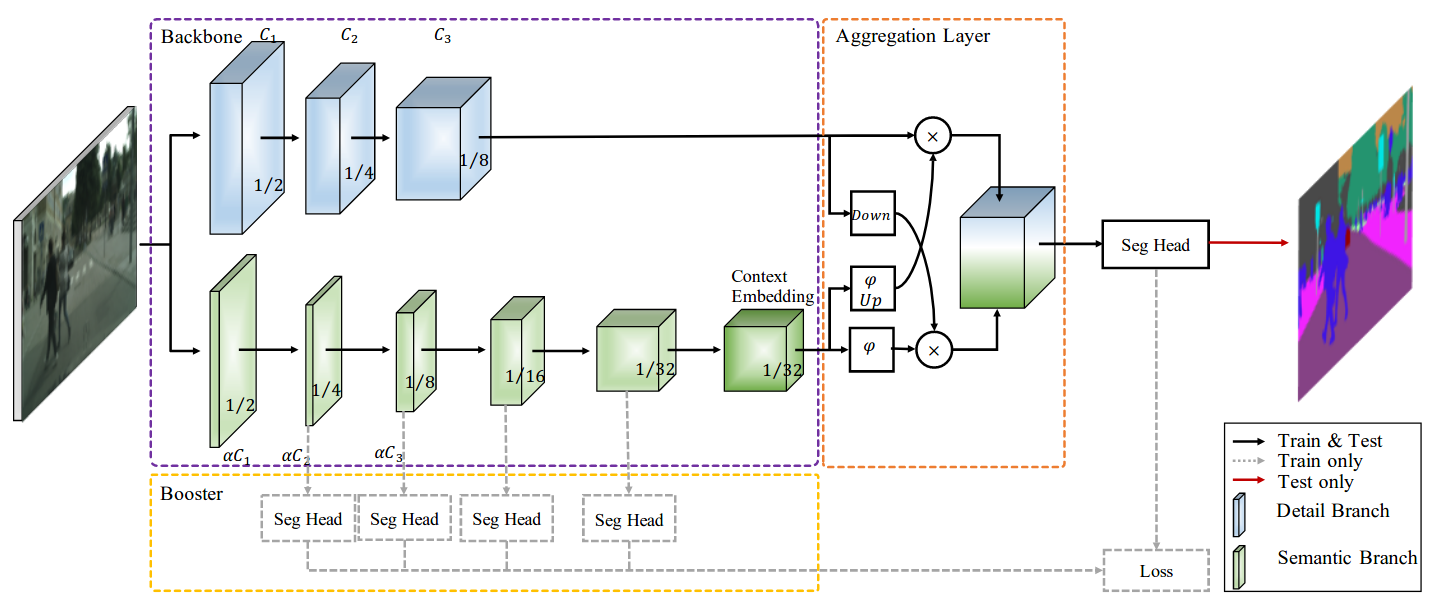
The low-level details and high-level semantics are both essential to the semantic segmentation task. However, to speed up the model inference, current approaches almost always sacrifice the low-level details, which leads to a considerable accuracy decrease. We propose to treat these spatial details and categorical semantics separately to achieve high accuracy and high efficiency for realtime semantic segmentation. To this end, we propose an efficient and effective architecture with a good trade-off between speed and accuracy, termed Bilateral Segmentation Network (BiSeNet V2). This architecture involves: (i) a Detail Branch, with wide channels and shallow layers to capture low-level details and generate high-resolution feature representation; (ii) a Semantic Branch, with narrow channels and deep layers to obtain high-level semantic context. The Semantic Branch is lightweight due to reducing the channel capacity and a fast-downsampling strategy. Furthermore, we design a Guided Aggregation Layer to enhance mutual connections and fuse both types of feature representation. Besides, a booster training strategy is designed to improve the segmentation performance without any extra inference cost. Extensive quantitative and qualitative evaluations demonstrate that the proposed architecture performs favourably against a few state-of-the-art real-time semantic segmentation approaches. Specifically, for a 2,048x1,024 input, we achieve 72.6% Mean IoU on the Cityscapes test set with a speed of 156 FPS on one NVIDIA GeForce GTX 1080 Ti card, which is significantly faster than existing methods, yet we achieve better segmentation accuracy.
Citation
@article{yu2021bisenet,
title={Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation},
author={Yu, Changqian and Gao, Changxin and Wang, Jingbo and Yu, Gang and Shen, Chunhua and Sang, Nong},
journal={International Journal of Computer Vision},
pages={1--18},
year={2021},
publisher={Springer}
}
Results and models
Cityscapes
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| BiSeNetV2 | BiSeNetV2 | 1024x1024 | 160000 | 7.64 | 31.77 | 73.21 | 75.74 | config | model | log |
| BiSeNetV2 (OHEM) | BiSeNetV2 | 1024x1024 | 160000 | 7.64 | - | 73.57 | 75.80 | config | model | log |
| BiSeNetV2 (4x8) | BiSeNetV2 | 1024x1024 | 160000 | 15.05 | - | 75.76 | 77.79 | config | model | log |
| BiSeNetV2 (FP16) | BiSeNetV2 | 1024x1024 | 160000 | 5.77 | 36.65 | 73.07 | 75.13 | config | model | log |
Note:
OHEMmeans Online Hard Example Mining (OHEM) is adopted in training.FP16means Mixed Precision (FP16) is adopted in training.4x8means 4 GPUs with 8 samples per GPU in training.