- prediction/image/ FastAPI 서버 Docker 환경 구성 - Dockerfile: PyTorch 2.1 + CUDA 12.1 기반 GPU 이미지 - docker-compose.yml: GPU 할당 + 데이터 볼륨 마운트 - requirements.txt: 서버 의존성 목록 - .env.example: 환경변수 템플릿 - DOCKER_USAGE.md: 빌드/실행/API 사용법 문서 - Dockerfile에 .dockerignore 제외 폴더 mkdir -p 추가 - .gitignore: prediction/image 결과물 및 모델 가중치(.pth) 제외 추가 - dbInsert_csv.py, dbInsert_shp.py 삭제 (미사용 DB 로직) - api.py: dbInsert import 및 주석 처리된 DB 호출 코드 제거 - aerialRouter.ts: req.params 타입 오류 수정 |
||
|---|---|---|
| .. | ||
| emanet_r50-d8_512x1024_80k_cityscapes.py | ||
| emanet_r50-d8_769x769_80k_cityscapes.py | ||
| emanet_r101-d8_512x1024_80k_cityscapes.py | ||
| emanet_r101-d8_769x769_80k_cityscapes.py | ||
| emanet.yml | ||
| README.md | ||
EMANet
Expectation-Maximization Attention Networks for Semantic Segmentation
Introduction
Abstract
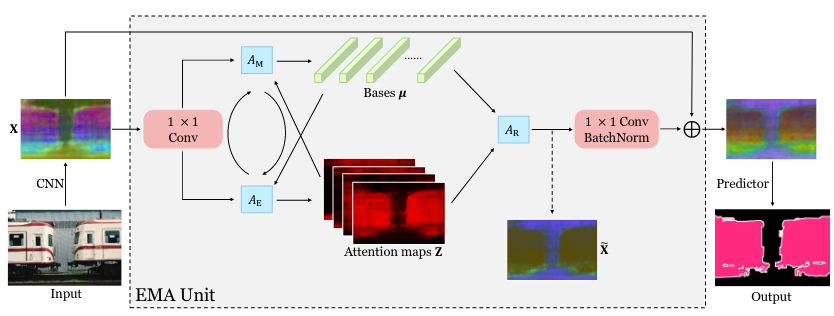
Self-attention mechanism has been widely used for various tasks. It is designed to compute the representation of each position by a weighted sum of the features at all positions. Thus, it can capture long-range relations for computer vision tasks. However, it is computationally consuming. Since the attention maps are computed w.r.t all other positions. In this paper, we formulate the attention mechanism into an expectation-maximization manner and iteratively estimate a much more compact set of bases upon which the attention maps are computed. By a weighted summation upon these bases, the resulting representation is low-rank and deprecates noisy information from the input. The proposed Expectation-Maximization Attention (EMA) module is robust to the variance of input and is also friendly in memory and computation. Moreover, we set up the bases maintenance and normalization methods to stabilize its training procedure. We conduct extensive experiments on popular semantic segmentation benchmarks including PASCAL VOC, PASCAL Context and COCO Stuff, on which we set new records.
Citation
@inproceedings{li2019expectation,
title={Expectation-maximization attention networks for semantic segmentation},
author={Li, Xia and Zhong, Zhisheng and Wu, Jianlong and Yang, Yibo and Lin, Zhouchen and Liu, Hong},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={9167--9176},
year={2019}
}
Results and models
Cityscapes
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| EMANet | R-50-D8 | 512x1024 | 80000 | 5.4 | 4.58 | 77.59 | 79.44 | config | model | log |
| EMANet | R-101-D8 | 512x1024 | 80000 | 6.2 | 2.87 | 79.10 | 81.21 | config | model | log |
| EMANet | R-50-D8 | 769x769 | 80000 | 8.9 | 1.97 | 79.33 | 80.49 | config | model | log |
| EMANet | R-101-D8 | 769x769 | 80000 | 10.1 | 1.22 | 79.62 | 81.00 | config | model | log |