- prediction/image/ FastAPI 서버 Docker 환경 구성
- Dockerfile: PyTorch 2.1 + CUDA 12.1 기반 GPU 이미지
- docker-compose.yml: GPU 할당 + 데이터 볼륨 마운트
- requirements.txt: 서버 의존성 목록
- .env.example: 환경변수 템플릿
- DOCKER_USAGE.md: 빌드/실행/API 사용법 문서
- Dockerfile에 .dockerignore 제외 폴더 mkdir -p 추가
- .gitignore: prediction/image 결과물 및 모델 가중치(.pth) 제외 추가
- dbInsert_csv.py, dbInsert_shp.py 삭제 (미사용 DB 로직)
- api.py: dbInsert import 및 주석 처리된 DB 호출 코드 제거
- aerialRouter.ts: req.params 타입 오류 수정
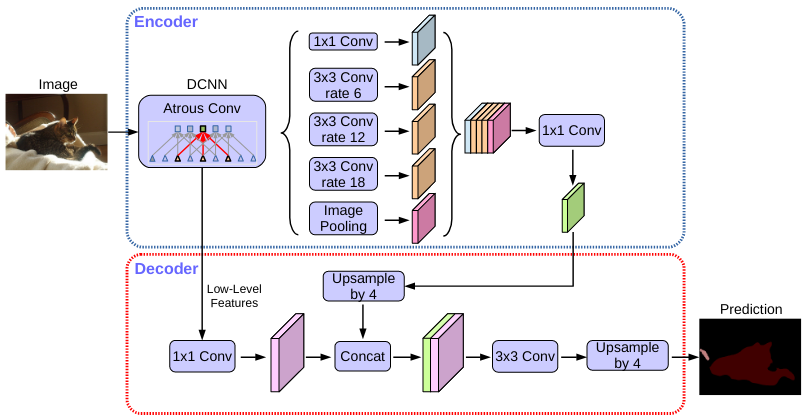
Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network. We demonstrate the effectiveness of the proposed model on PASCAL VOC 2012 and Cityscapes datasets, achieving the test set performance of 89.0% and 82.1% without any post-processing. Our paper is accompanied with a publicly available reference implementation of the proposed models in Tensorflow at this https URL.
Citation
@inproceedings{deeplabv3plus2018,title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},booktitle={ECCV},year={2018}}